Azure SRE Agent Explained: How AI-Driven Reliability Impacts Cloud Operations
An in-depth explanation of the Azure SRE Agent, how AI-driven reliability engineering works in practice, and when it delivers real operational value for modern cloud teams.

Cloud outages are no longer caused by broken infrastructure. They are caused by architectural complexity. Distributed systems, asynchronous workloads, and continuous delivery pipelines have made reliability a continuous engineering problem rather than an operational afterthought.
Microsoft’s answer to this reality is the Azure SRE Agent. Not another dashboard, not another alerting layer, but an AI-assisted reliability system that reasons about failures, understands context, and supports engineers during the moments that matter most.
What the Azure SRE Agent Actually Is
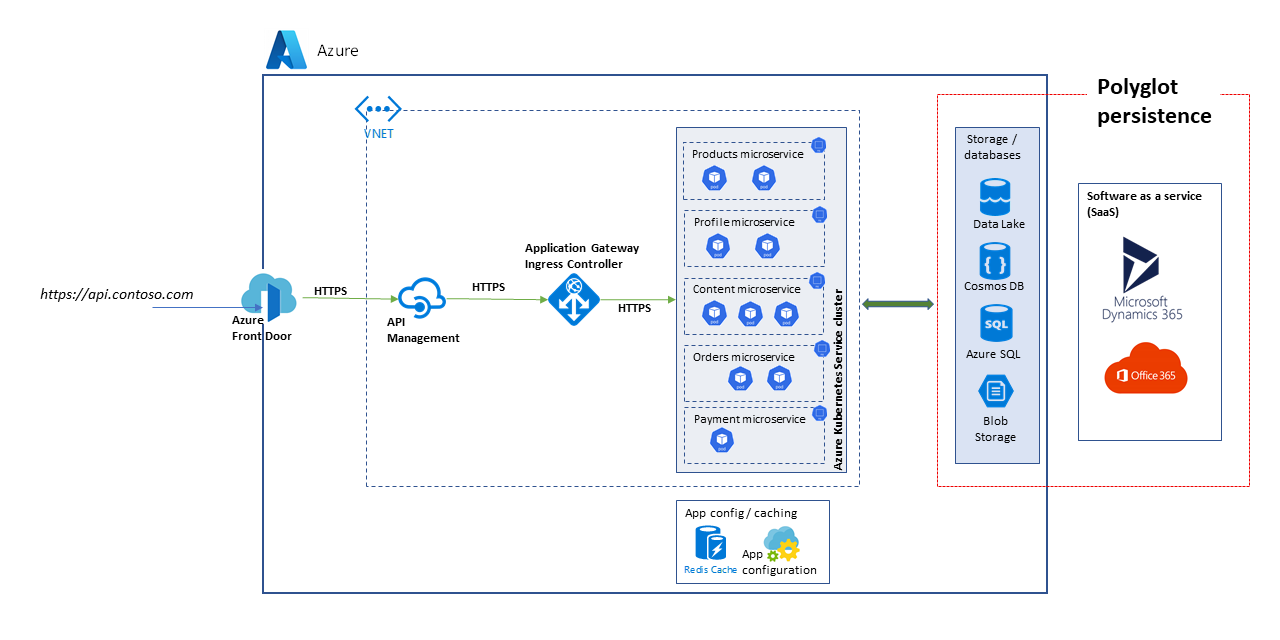
The Azure SRE Agent is an AI-powered reliability assistant that operates inside the Microsoft Azure ecosystem. Its role is to reduce operational friction by assisting with incident detection, diagnosis, and recovery.
What differentiates it from traditional monitoring tools is intent. The agent is not focused on surfacing metrics. It is focused on answering operational questions. Why is this happening? What changed? What is the likely impact if nothing is done?
Instead of handing engineers raw signals, it provides structured operational context.
Why Observability Alone Is No Longer Enough
Most teams already have logs, metrics, traces, and alerts. Yet incident response remains slow. The reason is not lack of data, but the cognitive load placed on humans during failures.
When systems degrade, engineers must correlate multiple sources, evaluate recent changes, and form hypotheses under time pressure. This is where mistakes happen and recovery time increases.
The Azure SRE Agent reduces this burden by pre-correlating signals and presenting a probable narrative. Engineers are no longer starting from zero. They are starting from an informed position.
How the Agent Behaves During an Incident
When abnormal behavior is detected, the agent groups related signals into a single incident and evaluates context across deployments, configuration changes, and historical patterns. This avoids alert storms and helps teams focus on root causes instead of symptoms.
In practice, the agent supports engineers in three concrete ways:
- It narrows down likely causes based on recent changes and past incidents
- It suggests recovery actions aligned with known operational patterns
- It accelerates decision-making without removing human control
Execution can be automated or approval-based, depending on how governance is configured.
Architectural Reality Check
This is not a magic reliability switch.
The Azure SRE Agent performs best in environments where system boundaries are clear and telemetry is consistent. If services are tightly coupled, logs are incomplete, or deployments are uncontrolled, the agent has limited signal quality to reason over.
In other words, it amplifies maturity. It does not create it.
Where This Actually Delivers Value
The real gains appear in environments where operational complexity has become a constraint rather than a feature. Think of platforms where uptime directly affects revenue or trust, and where engineers are frequently pulled into firefighting mode.
In those situations, the agent shortens incident resolution time, reduces alert fatigue, and preserves senior engineering capacity for architectural work instead of reactive operations.
For simple or low-traffic systems, the added value is limited. This is a scale tool, not a beginner tool.
Security, Governance, and Trust Boundaries
Allowing an AI system to influence production systems requires discipline. The agent supports access control, auditability, and approval workflows, but these are design decisions, not defaults.
A critical distinction must be made between what the agent may recommend and what it may execute. Organizations that blur this line introduce risk. Organizations that define it clearly gain leverage.
How Scalevise Helps You Apply This Correctly
This is where most teams get stuck.
At Scalevise, we help organizations determine whether their architecture and operations are ready for AI-assisted reliability. That includes validating observability foundations, defining safe automation boundaries, and integrating the Azure SRE Agent into existing incident workflows without disrupting governance.
We focus on outcomes, not feature activation. The goal is fewer incidents, faster recovery, and less operational drag on engineering teams.
If you are considering adopting this approach, or already experimenting but unsure how to move toward production use, we can help you make that transition deliberately.
Schedule a strategy session with Scalevise to assess fit, readiness, and impact.
Final Thought
The Azure SRE Agent is a signal of where cloud operations are heading. Reliability is becoming AI-assisted by default.
The organizations that benefit are not the ones that enable it fastest, but the ones that implement it with architectural discipline.